קורס בינה מלאכותית : RB20 – שיעור 7 מבנה רשתות ניירונים – חומר תיאורטי
חלק זה אפשר ללמוד אחרי הרצאה 8 או לפני , אני ממליץ קודם ללמוד הרצאה 8 ואז ללמוד את הרצאה 7 ואז שוב את הרצאה 8 – לפמי שפעם ראשונה עוסק בלמידת מכונה .
נילמד תא הנושאים בלמידת מכונה
-
Activation Function
-
Gradient Descent
-
BackPropagation
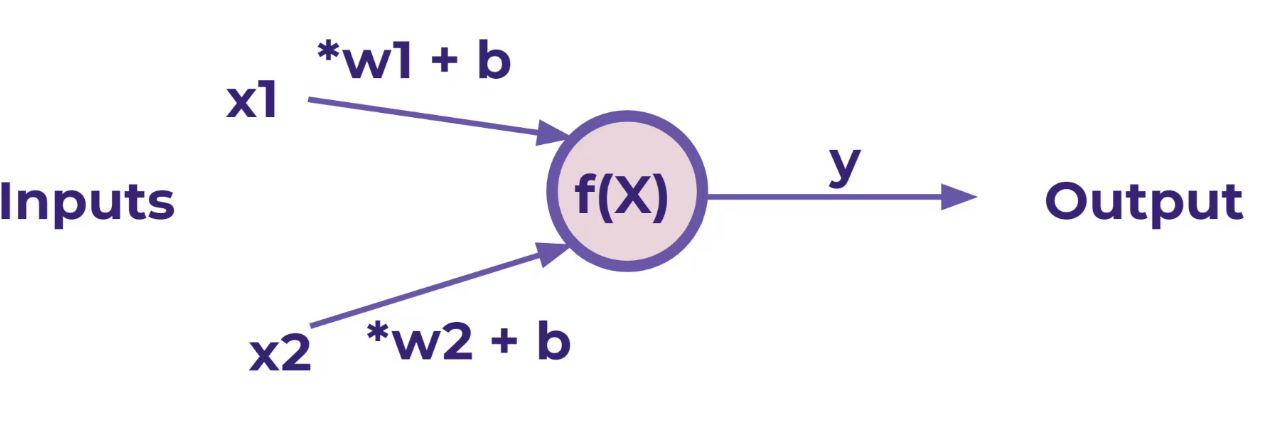
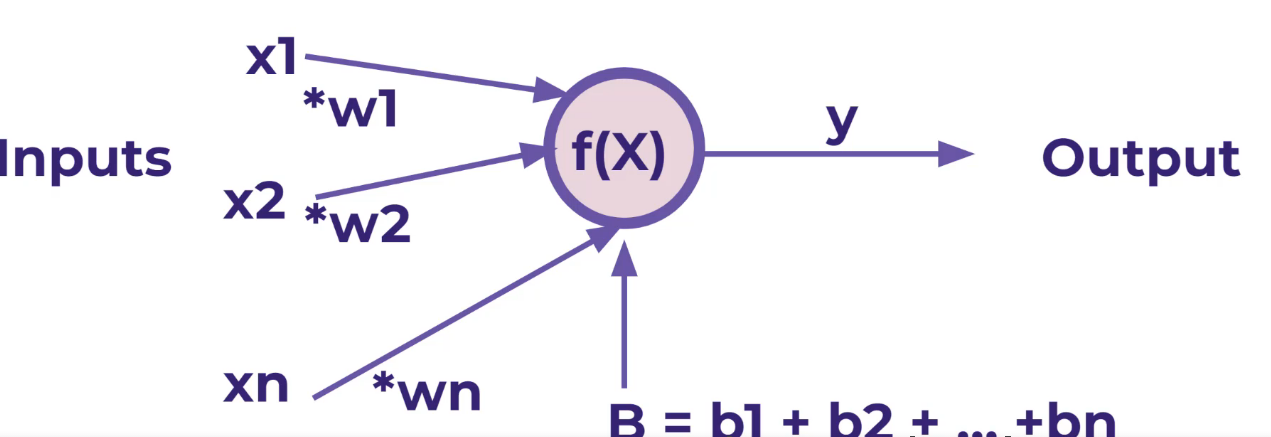
מודול PERCEPTRON
זה הוא ניירוון 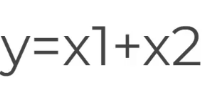
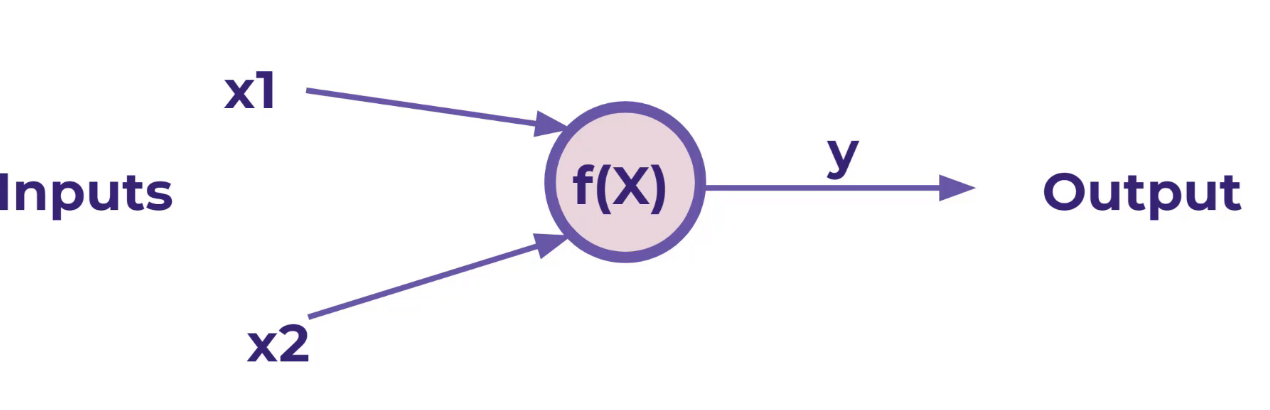 אנחנו רוצים שהמודל ידע לחשב בעצמו את ללא נוסחה !
אנחנו רוצים שהמודל ידע לחשב בעצמו את ללא נוסחה !
על מנת שיוכל ללמוד נוסף למודל הקדום משקלים W1 ו W2 אותם נששנה שוב שוב שוב עד שהמערכת תלמד בעצמה לחשב את X1 , X2 ללא נוסחה
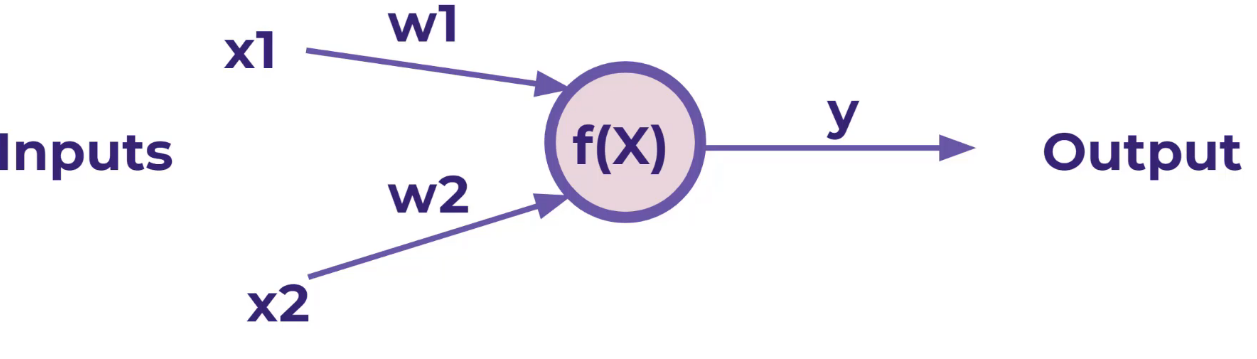
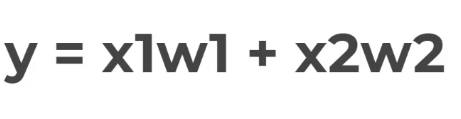
בעיה אחת שקיימת אם X הוא 0 במקרה זה נשדרג את הנסחה
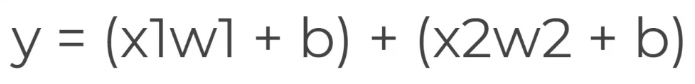
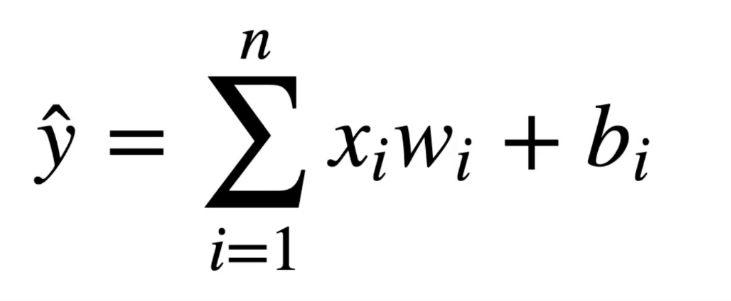
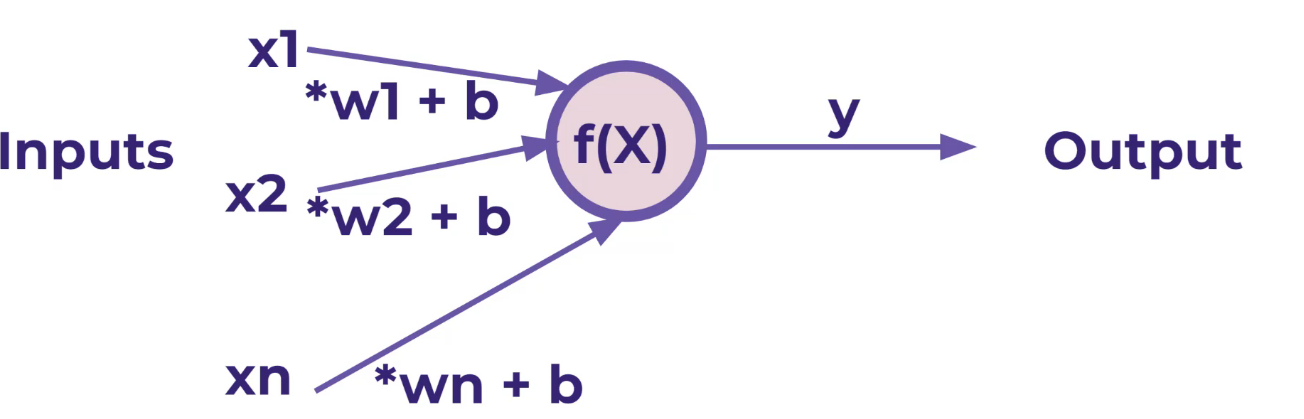
נעבור ל יש B שקול לכולם
סוגי רשתות
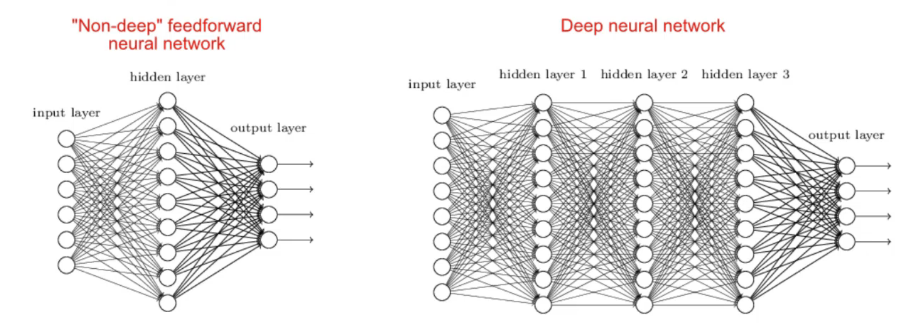
סוג הרשת מותאם לבעיה , בבעיות של קלסיפיקציה ננסה ש OUTPUT יהיה בין 0 ל 1
-
Activation Function
ראינו ש  לכן W הוא בעצם יתן את המשקל על X
לכן W הוא בעצם יתן את המשקל על X
מה שנעשה עבור כל NODE  העביר את Z דרך ACTIVATION FUNCTION
העביר את Z דרך ACTIVATION FUNCTION
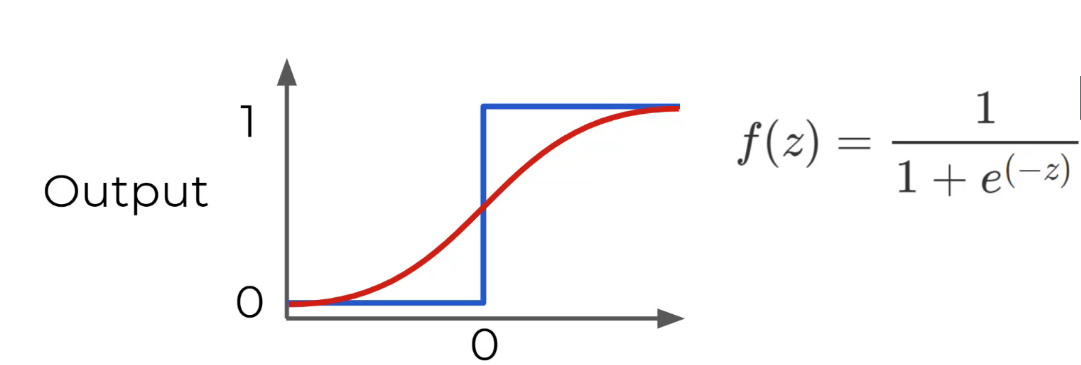
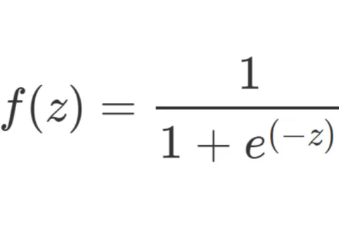 פונקציה זיגמואיד תתן לנו פלט דינמי בין 0 ל 1 אבל מדורג ולא קופץ בין 0 ל 1
פונקציה זיגמואיד תתן לנו פלט דינמי בין 0 ל 1 אבל מדורג ולא קופץ בין 0 ל 1
עוד סוגים של פונקצית אקטיבציה :
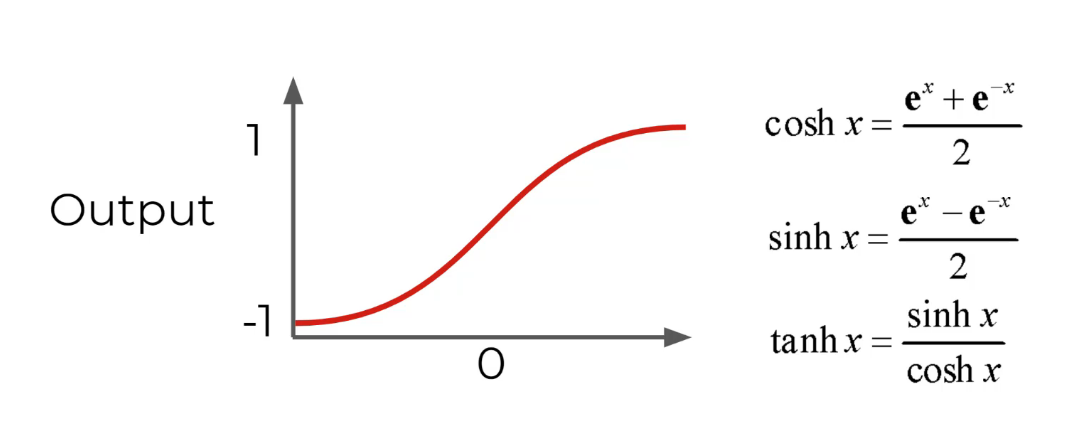
שימו לב ערך יהיה בין 1 – ל 1
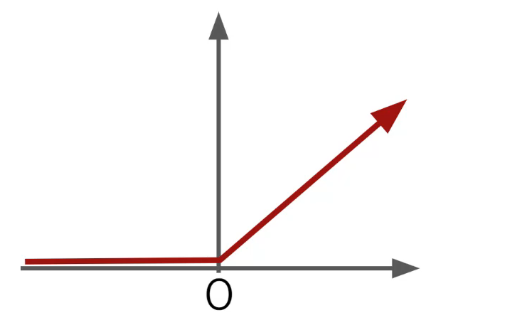
ReLU
https://en.wikipedia.org/wiki/Activation_function
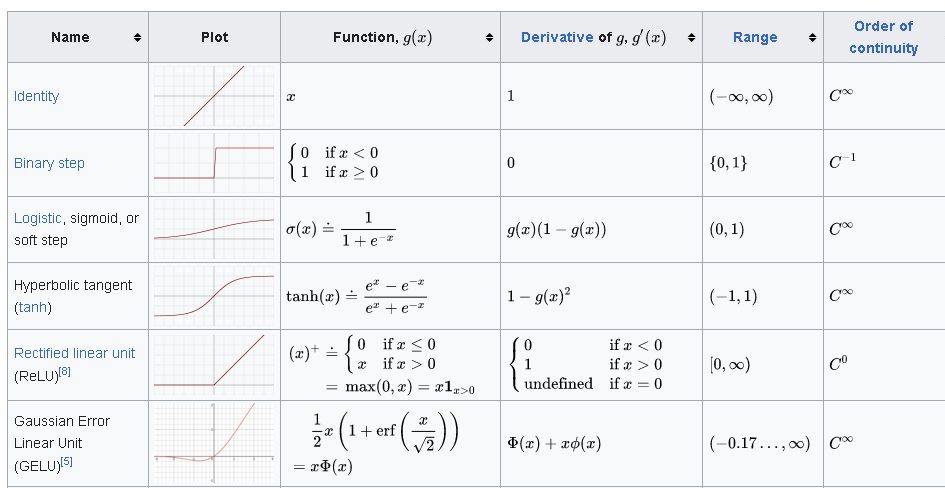

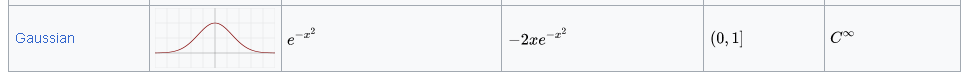
MULTI-CLASS CLASSSIFICATION
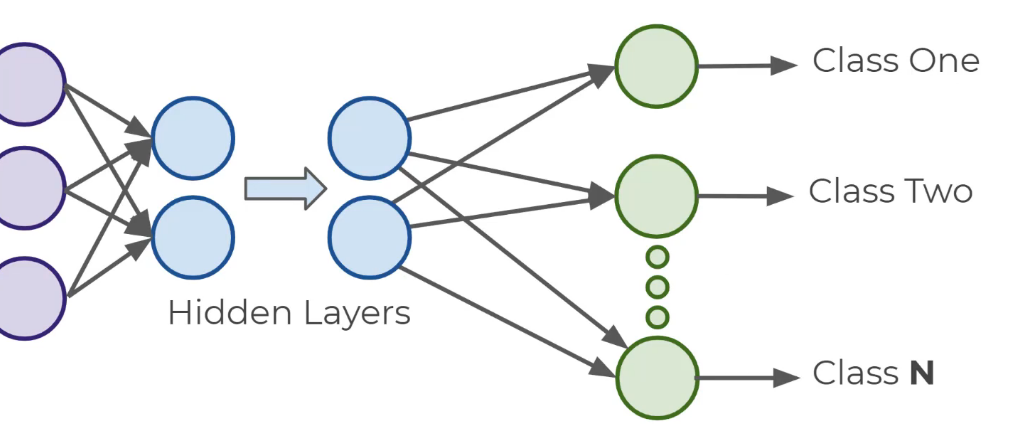
נקבל
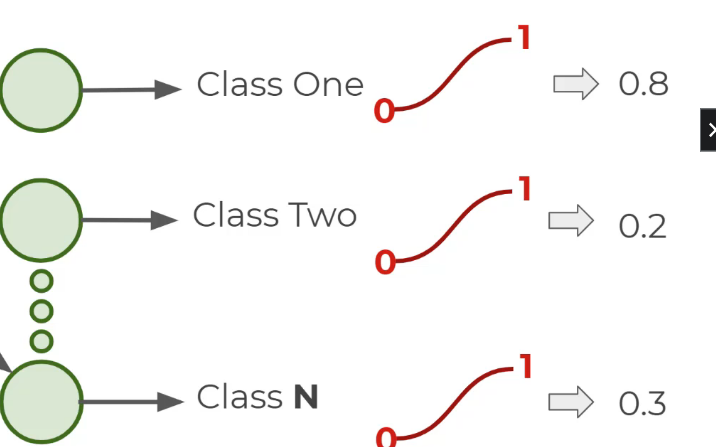
אפשר להשתמש ב SOFTMAX אבל אנחנו נקבל התפלגות
COST FUNCTION
LOST FUNCTION
על מנת לדעת כמה הרשת \ מודל בינה מלאכותית של למידת מכונה טוב נבצע את המהלכים הבאים
- את הפלט של הרשת של נתוני האימון נשווה לערכים האמיתיים והידועים LABLES
נשווה את Y-TEST ל Y-TRUE זה נעשה בעזרת ה COST FUCTION
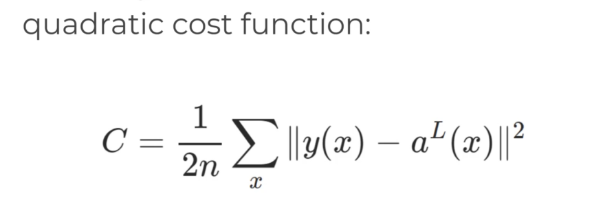
COST FUNCTION הינה סיכום של
של הפרמטרים הבאים
W – כל המשקלים
B – כל הבאייסים
S – הקלט
E – הערך שהיינו מצפים לקבל
צריך לשים לב למורכבות 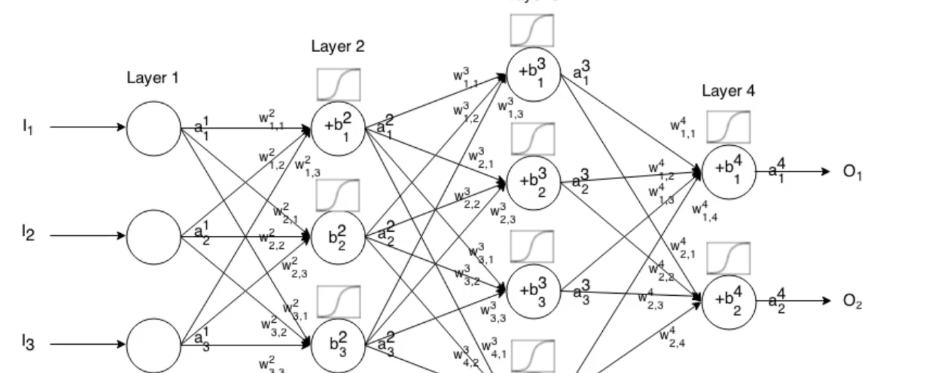
נניח שיש לנו רשת פשוטה של משקל איד בלבד
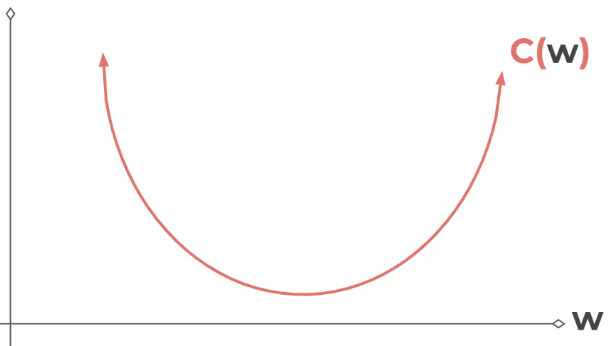
אנחנו בעצם "משחקים" ובודקים איזה ערך של W מגיע לאיזור המינימום של COST FUNCTION
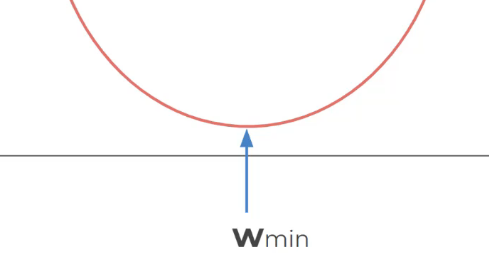
זה בעצם הערך שנירצא למשקל
בעיה הינה שיש בקשת עשרות משקלים ואפילו מאות ואלפים ולעשות נזרת ולהשוות ל 0 לא אפשרי כלל בזמן חישוב קצר
לכן מצאו שיטה אחרת ומהירה מאוד מאוד
GRADIEN DESCENT
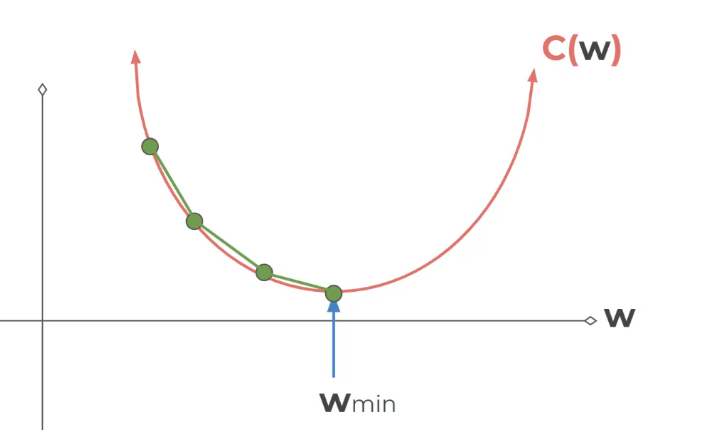
נחזוק להתסכל על משקל אחד – אבל השיטה טובה להרבה מאוד משקלים
נחבר נקודה אחת ואז לא נעבור לנקודה ליד אלא נקפוץ
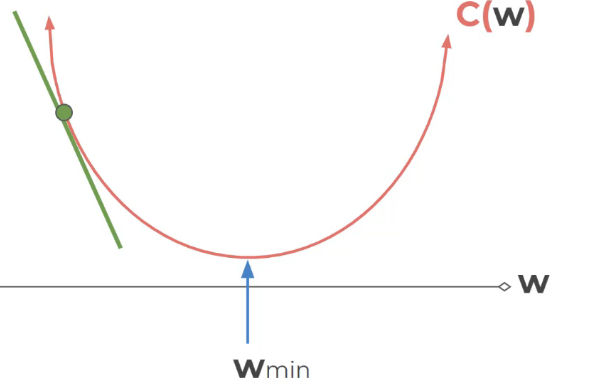
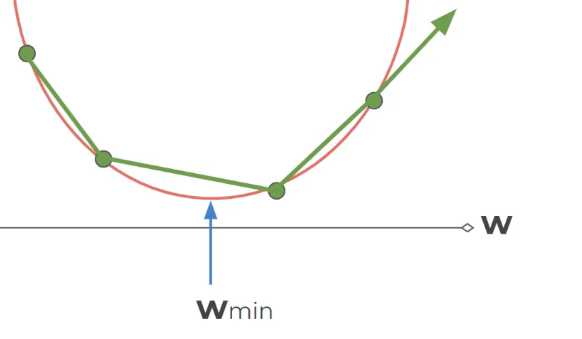
overSHoothing צעדים גדולים נפספס את המינימום
צעדים קטנים יקח הרבה מאוד זמן – לכן צריך למצוא משהו אופטימלי
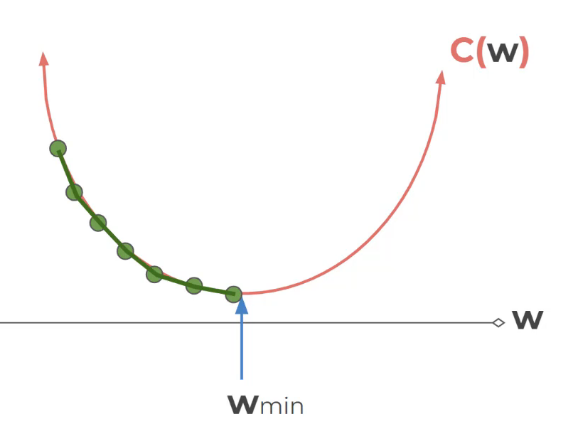
Learning rate
זה הזמן \ קצב שלוקח למערכת ללמוד
אפשרי שהקפיצות לא יהיו אותו גודל אלא בקפיתות בגודל משתנה
אנחנו נשתמש ב ADAM שהוא משתשמש באופטימזציה טובה
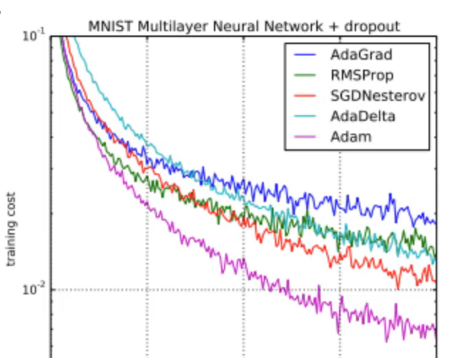
עבור בעיות קלסיפקציה נשתמש ![]()
BackPropagation
הינו הנושא המורכב ביותר